Knowledge Byte: What Is Hadoop and How Has It Been Used?

Cloud Credential Council (CCC)

If you have the remotest interest in expanding your big data knowledge, you must have encountered the word Hadoop before. What is it precisely?
● It is an open-source framework for large scale data processing.
● It allows for large data sets to be processed on commodity hardware, as opposed to high-end servers.
● A typical Hadoop installation can grow as necessary and does not require a large up-front investment.
● It achieves this by splitting the data processing task amongst the available machines and coordinating their action.
Usage Example
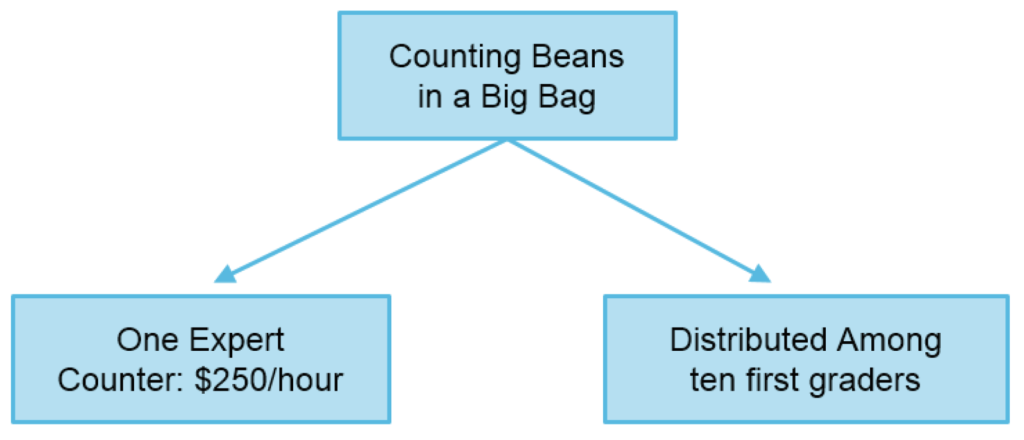
An analogy will help in illustrating how Hadoop works. Let’s imagine that we need to count a big bag of beans. We can hire an expert bean counter at $250/hour to do the job for us. We will give the bag to the counter and after some time they will come back with the final result. Let’s say the bag contains 100,000 beans. Alternatively, we can ask a group of ten first graders to do the same job for us. In this case, we will split the bag into ten piles of beans with approximately equal sizes. Each of our pupils then will count their pile and give the results to their teacher. The teacher will total their results and provide us with the final number. If in the process one of the pupils needs to leave, the teacher will split his or her pile amongst the remaining students.
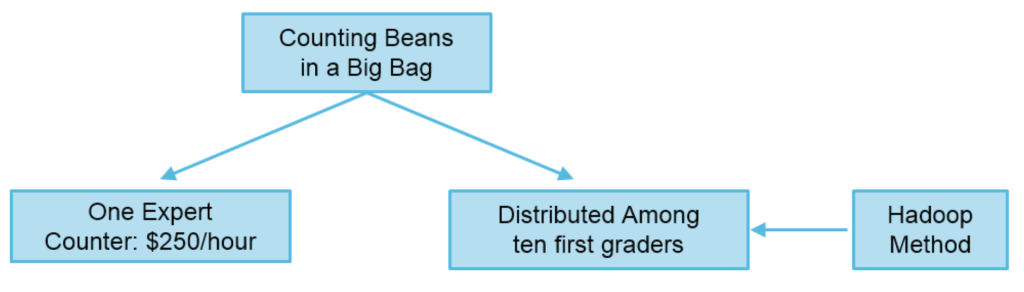
Hadoop works by splitting a large data set into smaller parts, distributing each one of these to be processed on a different machine and then assembling the output from each processing node into a single set of results. In the process, Hadoop manages the fault-tolerance of the cluster and coordinates the actions of individual nodes. For example, if a node fails, the tasks assigned to it will be re-distributed amongst the remaining nodes by Hadoop.
Concepts

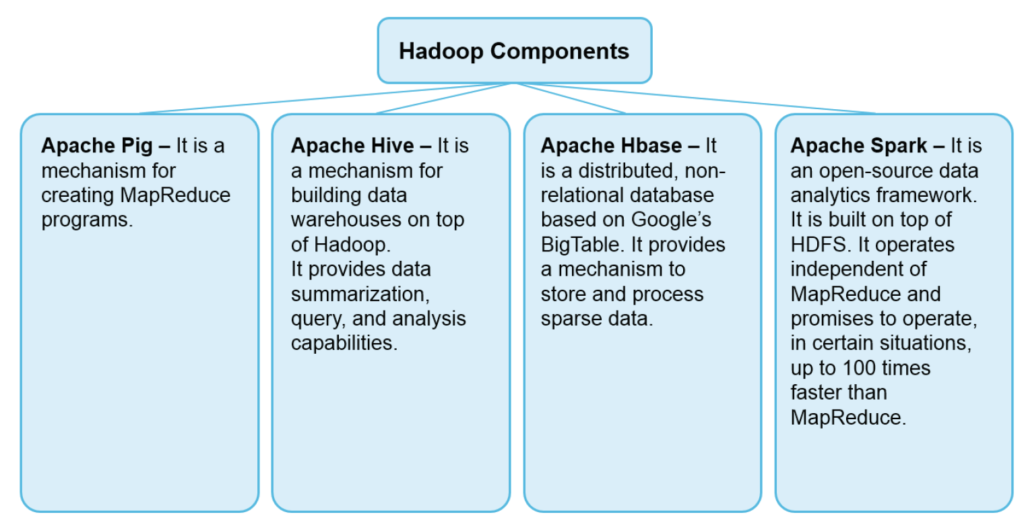
Use Cases
EBay
● 532 nodes cluster (8 * 532 cores, 5.3PB)
● Heavy usage of Java MapReduce, Apache Pig, Apache Hive, and Apache HBase
● Used it for search optimization and research
Last.fm
● 100 nodes
● Dual quad-core Xeon L5520@2.13 GHz, 24GB RAM, 8TB storage
● Used for charts calculation, royalty reporting, log analysis, A/B testing, and large scale audio feature analysis over millions of tracks (Source).
Courses to help you get
results with Big Data
Sorry, we couldn't find any posts. Please try a different search.
Never miss an interesting article
Get our latest news, tutorials, guides, tips & deals delivered to your inbox.
Keep learning


